Context Engineering
Table of Contents
Writing code isn’t the bottleneck anymore. Agents can do the implementation, so the hard part now is making sure they understand the right things at the right time.
People call this context engineering. You give agents the right information, then check the conclusions they come to. For a small change it’s quick. For a big codebase spread across a few repos, it’s most of the work. I spend a lot of time going back and forth with agents, asking different questions, explaining what I want, and figuring out what they actually did.
Prior Art #
Kiro and Spec-Kit already handle the research → spec → implement loop.
What they don’t answer is what happens to all those markdown files afterward. Traceability sounds nice, but a pile of dense markdown files sitting next to the code isn’t really it:
- They make cross-repo changes harder to track.
- They assume you’ll go back and read them, which you won’t.
- They’re overkill for small changes.
So how do you do the back-and-forth that sharpens what you want without generating a pile of files nobody maintains?
A PoC for Context Engineering #
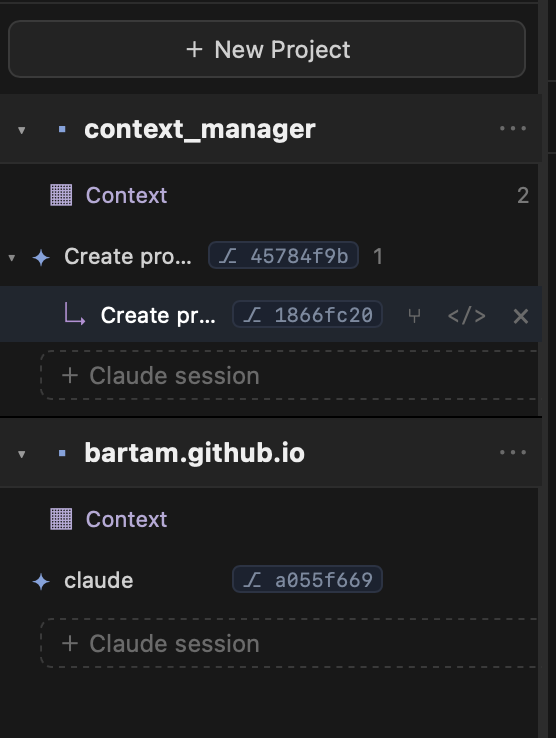
I built a quick proof of concept to play with this. It has two parts: forking and a context scratchpad.
Forking #
You can fork or rewind a Claude session whenever you want, and each fork keeps the conversation history.
This helps when you’re working through an idea. Start high level, branch off to nail down the details, then pull what you learned back into the main thread. Claude Code already does forking, so this isn’t new. But having it in the UI makes it easier to keep track of, so I can jump between tasks and projects and still know what belongs where.
Context Scratchpad #
As you go, you can copy agent responses into a scratchpad, and then start new sessions with that scratchpad already loaded in.
This is handy for cross-repo work, where I want quick notes tied to the task that don’t belong in CLAUDE.md and would otherwise get lost in some architecture doc. It lets me treat a project as a workspace instead of tying it to one repo.
And for the small tasks where something unexpected comes up (so, every day), I can work through it in the scratchpad instead of spinning up a markdown file I’ll have to maintain.
What Context Engineering Looks Like #
Both of these get at the same thing: how to refine what you want without piling up files. Forking lets you go down a path and come back instead of cramming everything into one long thread. The scratchpad keeps the useful context near the task and lets the rest go.
That’s what the job looks like now. The implementation mostly takes care of itself; the work is in the conversation that gets you there. Context engineering just means taking that part seriously and being deliberate about what you hand the agent.